
OpenAI o1: 복잡한 추론을 위한 새로운 언어 모델 도입


OpenAI가 새로운 대형 언어 모델 o1을 선보였다. 이 모델은 강화 학습을 통해 복잡한 추론을 수행할 수 있도록 훈련되었으며, 최종 답변을 생성하기 전에 내부적으로 깊이 있는 사고 과정을 거친다. 이를 통해 AI의 추론 능력이 한층 더 향상되었다.
OpenAI의 o1은 경쟁 프로그래밍 질문(Codeforces)에서 상위 89%의 성과를 기록했으며, 미국 수학 올림피아드(AIME) 예선에서는 미국 상위 500명 학생과 비슷한 수준의 결과를 보였다.
또한, 물리, 생물학, 화학 문제를 다루는 GPQA 벤치마크에서는 인간 박사 수준의 정확도를 뛰어넘는 성과를 거두었다. 현재 모델의 사용 편의성을 개선하기 위한 작업이 진행 중이지만, OpenAI는 초기 버전인 o1-preview를 ChatGPT와 신뢰할 수 있는 API 사용자들에게 공개했다.

강화 학습과 추론 능력
대규모 강화 학습 알고리즘은 모델이 사고 과정을 통해 생산적으로 생각할 수 있도록 훈련한다. o1은 반복적인 훈련을 통해 꾸준히 성능이 향상되었으며, 더 많은 계산 자원을 사용해 생각하는 시간이 길어질수록 더욱 높은 성과를 보였다. 이 접근 방식의 확장 가능성은 기존의 대형 언어 모델 사전 학습 방식과 크게 달라, 이에 대한 연구가 계속 진행되고 있다.
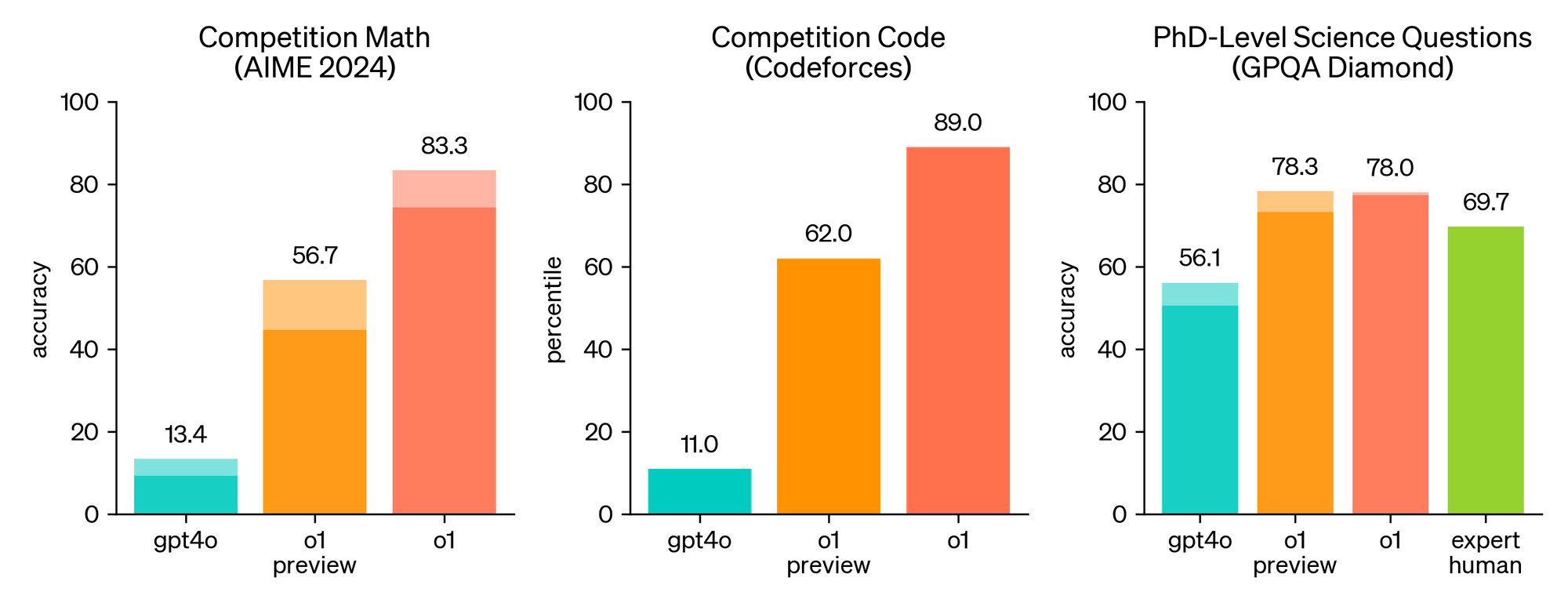
성능 평가 결과
o1의 성능을 확인하기 위해 인간 시험과 다양한 머신러닝 벤치마크에서 모델을 평가했다. 그 결과, 대부분의 추론 중심 작업에서 GPT-4o를 크게 앞서는 성과를 보였다.
특히 AIME 시험에서는 GPT-4o가 평균 12%의 문제를 해결한 데 비해, o1은 74%를 해결했고, 학습된 스코어링 기능을 적용하자 성능이 93%까지 향상되었다. 또한, GPQA-diamond라는 어려운 지능 벤치마크에서도 인간 박사 전문가들을 뛰어넘는 성과를 보여주었다.
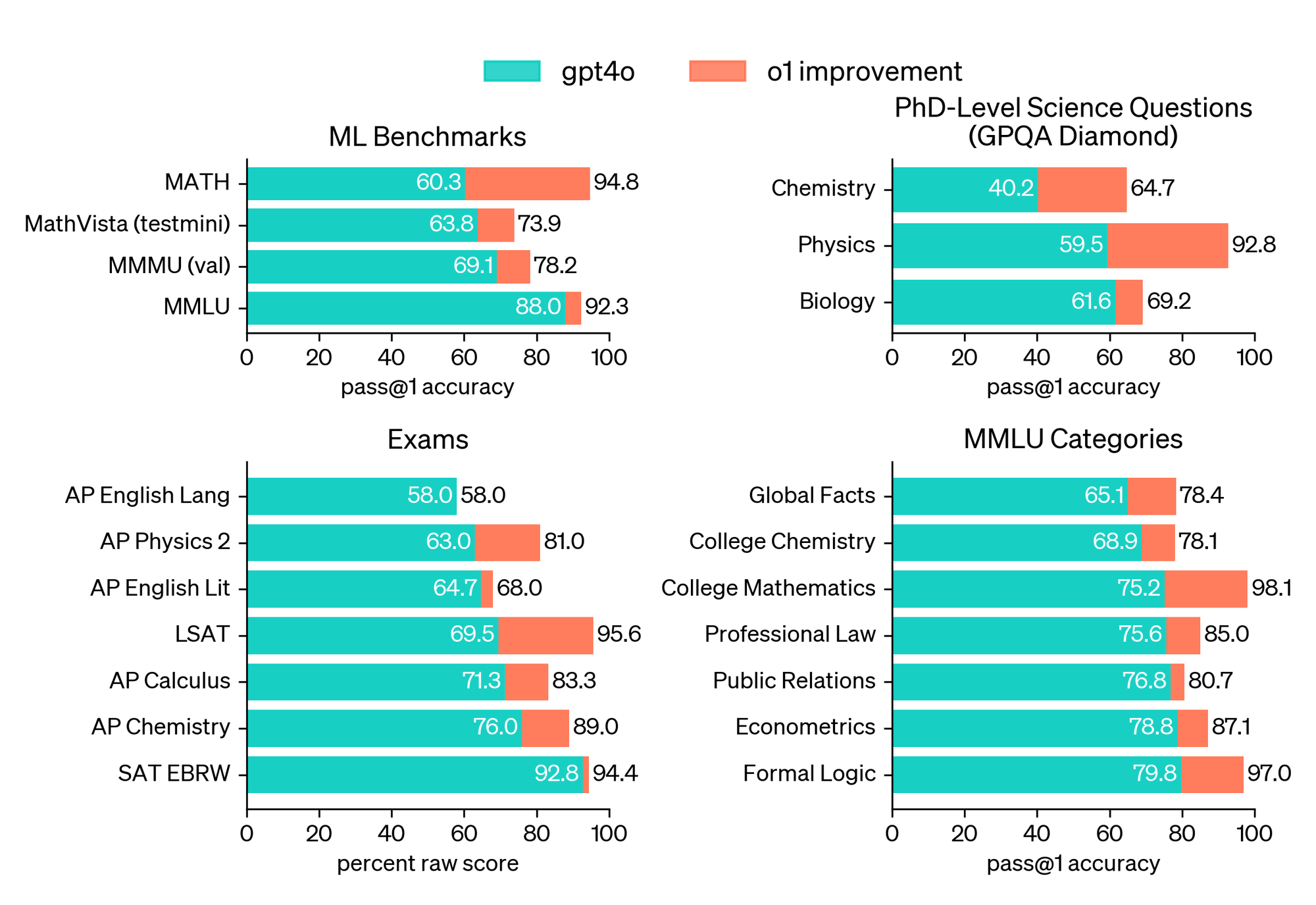
연쇄적 사고(Chain of Thought)
o1은 어려운 문제에 답하기 전에 연쇄적 사고 과정을 거친다. 이를 통해 모델은 복잡한 문제를 단순한 단계로 나누어 해결하고, 잘못된 접근을 인식하고 수정하는 능력을 배운다. 이 과정은 모델의 추론 능력을 크게 향상시키며, 문제 해결에 있어 보다 효율적인 접근 방식을 사용하게 한다.
코딩 능력 향상
o1을 기반으로 프로그래밍 능력을 더욱 향상시키기 위해 훈련한 모델은 2024년 국제 정보 올림피아드(IOI)에서 49%의 성과를 기록했다. 모델은 경쟁 프로그래밍 대회(Codeforces)에서도 인간 경쟁자들보다 우수한 성과를 보이며 코딩 실력을 입증했다.
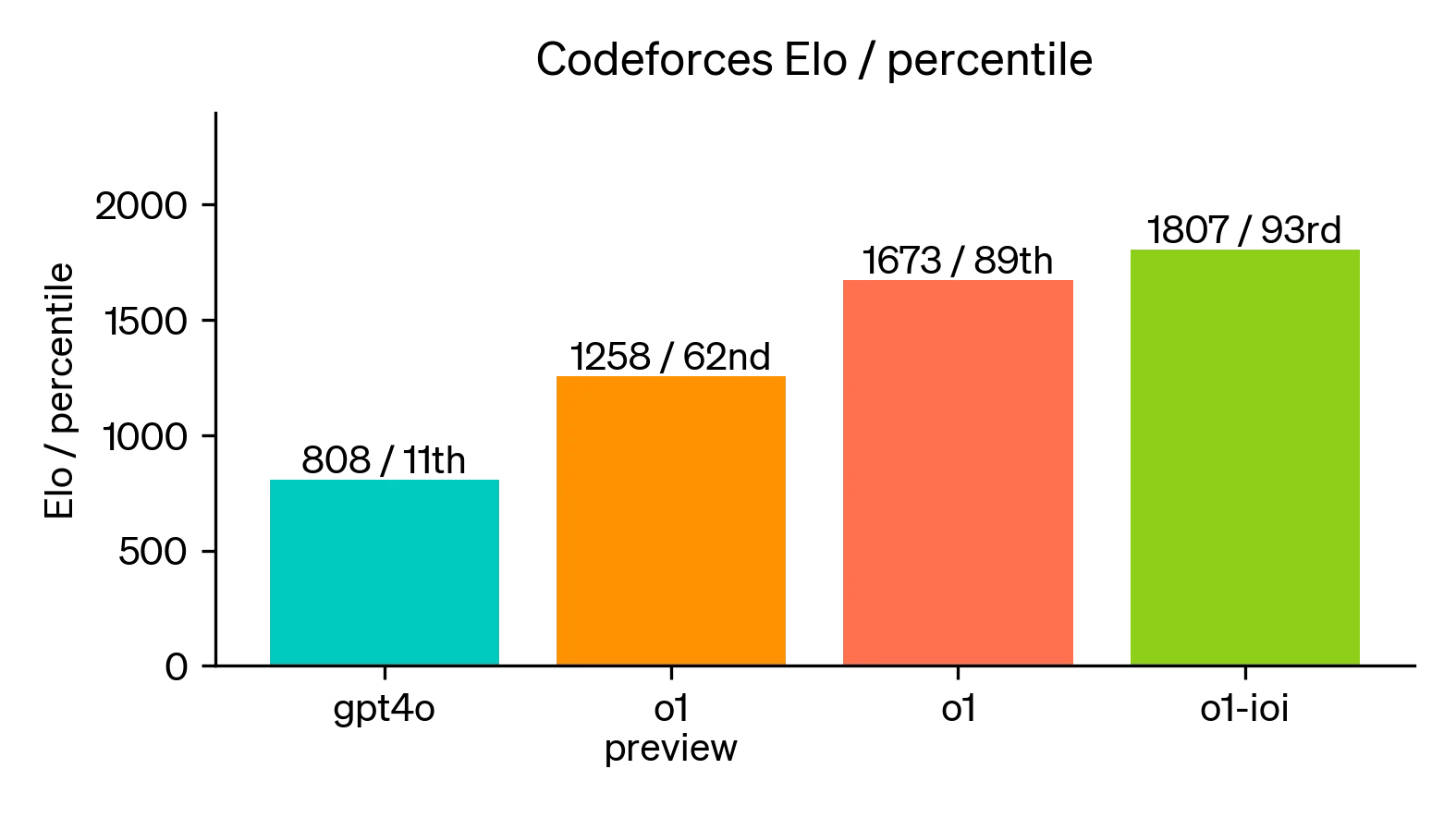
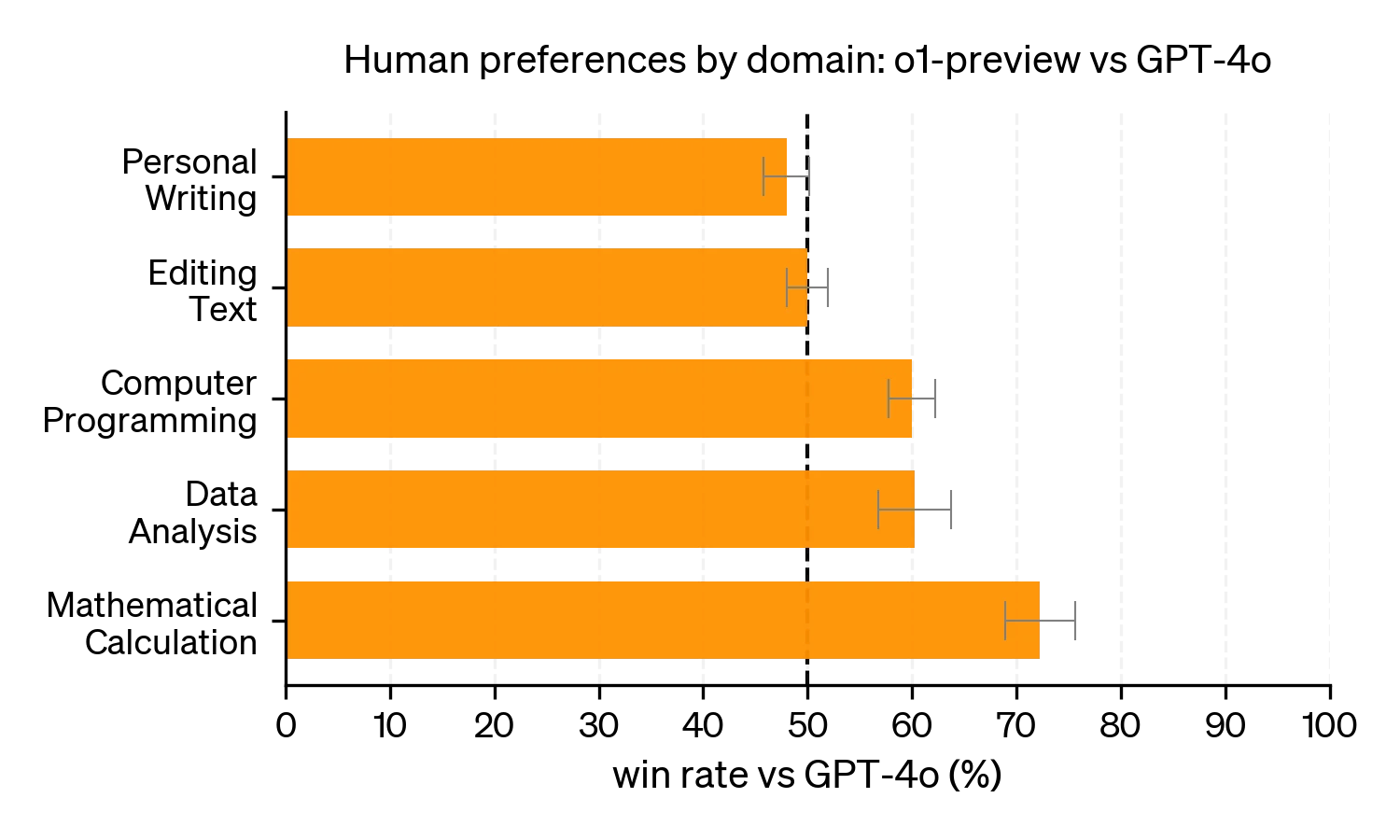
안전성 강화
연쇄적 사고를 통해 모델의 안전성과 정렬 능력도 향상되었다. 모델이 사고하는 과정을 관찰함으로써 인간의 가치와 원칙을 학습할 수 있었으며, 이를 통해 o1-preview는 주요 안전성 평가에서 GPT-4o보다 훨씬 뛰어난 성과를 기록했다.
결론
o1은 AI 추론의 새로운 가능성을 열어준다. 향후 더 개선된 모델을 공개할 계획이며, 이 새로운 추론 능력이 과학, 코딩, 수학 등 다양한 분야에서 AI의 활용 가능성을 크게 확대할 것으로 기대된다. 사용자가 이 모델을 통해 일상 업무에서 어떤 변화를 경험하게 될지 기대된다.



